This is a guest blog by Ranjan Bhattacharya
Companies, large and small, across multiple industries, are all attempting to build Machine Learning (ML) models to gain competitive advantages. However, ML models are much harder to consistently deploy to production than traditional software. According to this report by Algorithmia, 2020 State of Enterprise Report, only 22% of the surveyed companies have successfully deployed a model, and in spite of increased spending, 43% had difficulty scaling machine learning projects to their company’s needs.
Starting on their ML journeys, companies often tend to focus initially on building a data science team for developing sophisticated ML models to extract critical business insights from data. However, lasting business value, and ROI, come from getting the solution to the next stage: validated, scaled and deployed to production, monitored and optimized post-deployment. It is in these stages of the lifecycle most companies have difficulty.
Software providers face similar challenges in deploying ML much as enterprise businesses do. Addressing them allows opportunities for SaaS companies to provide solutions which incorporate ML deployment best practices or tools for deploying and maintaining ML solutions.
In traditional software engineering, a set of principles and practices collectively called DevOps, allows rapid, repetitive and reliable releases, and unites development, deployment, and operational monitoring. These practices include code versioning, incremental releases, testing automation, integration and delivery, and operational monitoring. DevOps has been successfully employed in SaaS businesses and is considered a best practice for several years.
For ML systems, however, the availability and adoption of a similar set of principles, and practices (MLOps) is less common. As shown in the diagram below, an ML system can comprise a large and complex infrastructure, with cross-functional responsibilities spanning multiple teams:
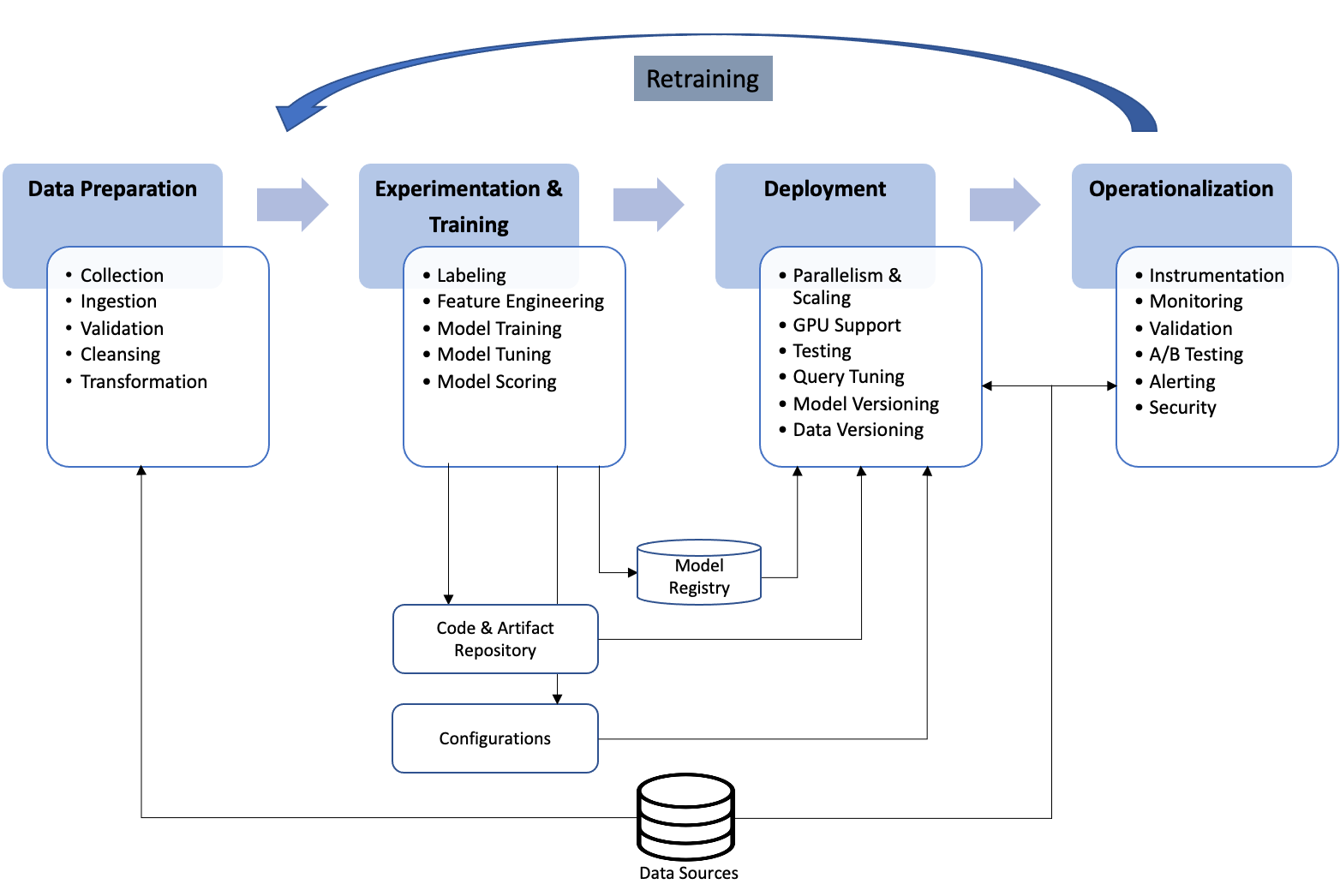
ML systems differ from traditional software systems in other important ways as well:
Versioning: During the experimentation phase, data scientists use training data sets to explore the data and arrive at the right predictive model with different combinations of artifacts like features, algorithms, parameters, and configurations. To allow the data scientists quickly switch between the various experiments, these artifacts should be tracked and versioned.
Scaling: For ML code to become ready for production, often the code developed during the exploration phase needs to be rewritten for scalability. For example, what has been developed in Jupyter notebooks on an ML engineer’s laptop, may have to be retargeted for a Spark cluster, or maybe even a GPU, requiring different sets of skills.
Testing: Testing for ML systems is more involved as it encompasses testing for ML code, model and data quality, bias detection, across multiple implementations in different platforms. Moving various artifacts of an ML system through different steps of a deployment pipeline also needs additional and extensive testing.
Monitoring: Once deployed, ML systems need to be continuously monitored not only for their runtime performance, but also for their quality of predictions. ML models tend to degrade and drift over time, reducing the predictive power of a model, as the data used for training a model becomes stale and no longer reflects real-world scenarios.
Governance: As ML models often deal with confidential and private data, access control policies need to define roles and responsibilities throughout the entire ML development pipeline for access to the models and the underlying data. Governance policies also need to include metrics for bias detection, auditability and explainability, as ML models are increasingly coming under regulatory purview.
Companies wishing to take advantage of the tremendous gains that are happening in the field of ML and are encountering challenges in moving their ML models to production should encourage rapid adoption of MLOps. This is also an excellent opportunity for software providers to lead in the deployment of ML and will allow themselves and their customers to be able to:
- Quickly deploy and test new models
- Compare impacts of changes to models
- Reproduce and retrace important model-driven business decisions
- Rapidly rollback to earlier models due to non-performance of a recent upgrade
- Retrain models when new data sets become available
- Address questions surrounding model security, privacy, and bias
In subsequent posts, we will continue to explore additional aspects of MLOps, including maturity models, best practices and tools.

Ranjan is a senior technology leader from Boston who has built and led technology teams to build innovative SaaS solutions, several of them incorporating Data Science/Machine Learning, in different companies across multiple industries.

One thought on “Towards a More Mature Machine Learning Lifecycle–An Introduction to MLOps”